한국기술교육대학교 온라인 평생교육원 - Python 기반 SQL 프로그래밍 첫 번째 강의를 듣고 정리한 내용입니다
요약
- DBMS가 필요한 이유는 데이터를 효율적으로 다루기 위해 등장했다.
- DB화란, 현실세계에 있는 데이터를 데이터베이스 객체로 만들고 저장하는 과정을 가리킨다.
- RDBMS(관계형 데이터베이스 시스템)에서는 데이터 모델링이 크게 개념 모델링, 논리 모델링, 물리 모델링 세 단계로 구성된다.
- RDBMS의 데이터베이스를 다룰 때 사용하는 언어가 SQL이며, 데이터베이스에 요청을 통해 필요한 정보를 가져올 수 있다.
데이터 모델링의 3단계
- 개념 모델링(Conceptual Modeling)
현실 세계의 데이터와 관련된 개념을 식별하고, Entity, attributes, Relationship 등의 개념적인 요소로 표현한다. 즉, 개체를 추출하고 관계를 정의하는 Entity-Relationship을 바탕으로 E-R diagram을 만든다.
찾아보니 entity간의 관계를 이해하고 문서화하는 것을 목표로 한다고 한다. 비즈니스 분석가나 아키텍트와 같은 전문가들이 협업을 통해 데이터베이스를 추상화하고 문서화하는 과정이라고.
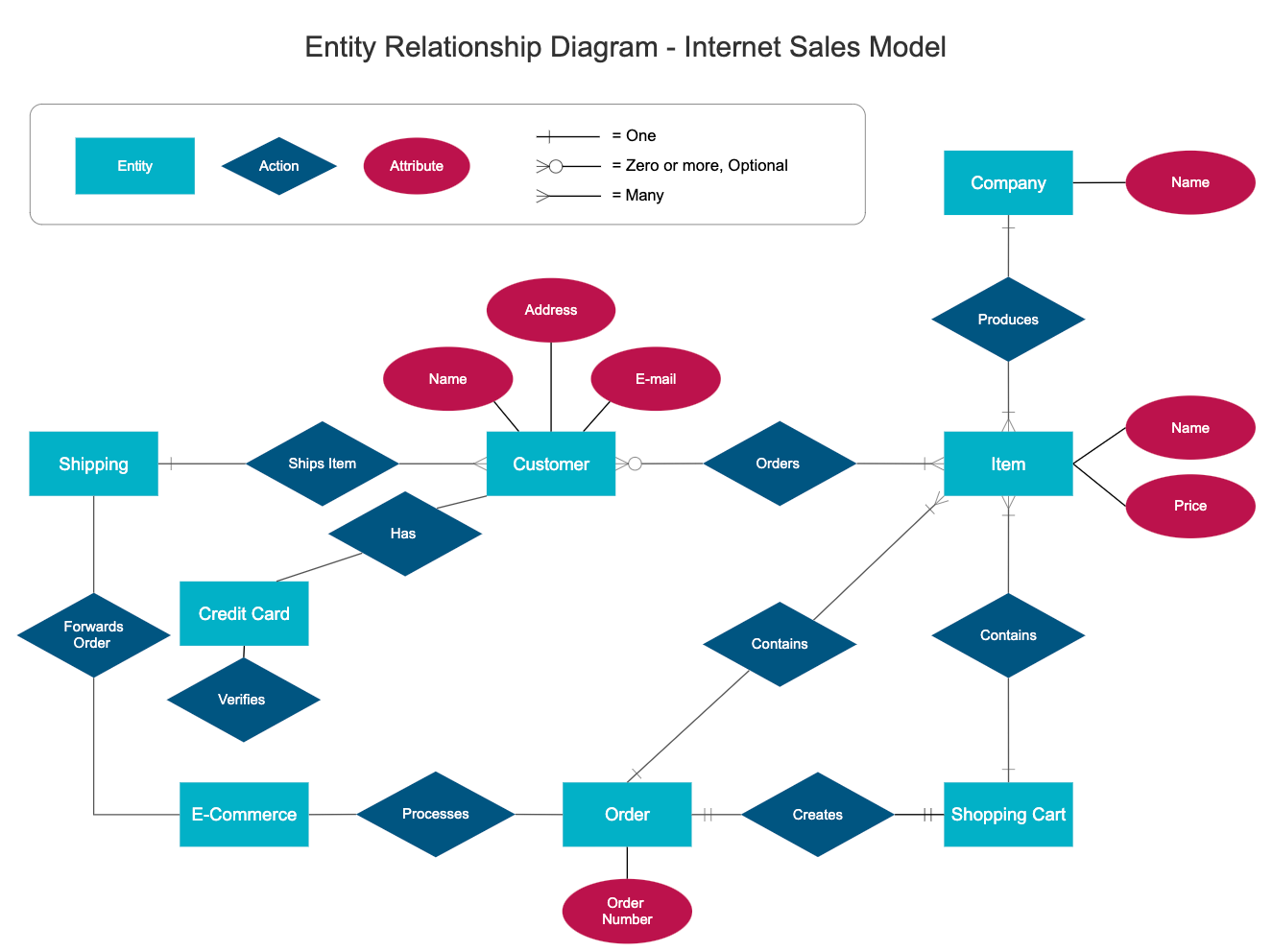
- 논리 모델링(Logical Modeling)
개념모델링을 기반으로 데이터베이스의 논리적인 구조를 설계한다. 이 단계에서는 개념 모델을 논리적인 테이블로 변환하고 각 테이블의 속성과 관계를 정의한다. 이때, 데이터베이스의 중복을 최소화하기 위해 데이터베이스의 정규화가 수행된다.

- 물리 모델링(Physical Modeling)
개념 모델링과 논리 모델링을 통해 데이터베이스의 구조와 개념이 이해된 후에는 SQL을 활용해 데이터베이스를 구현한다. 테이블의 스키마, 인덱스, 파티셔닝 등과 같은 물리적인 구조가 설계되며, 데이터베이스 시스템의 성능이나 용량을 고려해 데이터 저장 및 접근 방법을 최적화한다고. 이때 SQL을 활용해 추상화를 진행한다고 보면 된다.
목적에 따른 SQL 명령어의 분류
- DDL: Data Definition Language, 데이터 테이블을 정의하는 SQL 명령어. 예시)
CREATE,ALTER,DROP - DML: Data Manipulation Language, 데이터 테이블 내 데이터를 조작하는 명령어. 예시)
INSERT,SELECT,UPDATE,DELETE - DCL: Data Control Language, 데이터에 접근할 수 있는 권한을 관리하는 명령어. 예시)
GRANT,REVOKE
이 외에도 함수와 연산자 등이 있다고 한다. sql 함수 참고
- 데이터 조회 및 조작 함수: 데이터 필터링, 정렬, 그룹화 및 집계 등을 위해 사용하는 함수 (엑셀이랑 비슷한게 많다!)
- 집계 함수:
SUM(),AVG(),COUNT(),MIN(),MAX() - 문자열 함수:
CONCAT(),SUBSTRING(),UPPER(),LOWER(),REPLACE() - 날짜 및 시간 함수:
DATE(),TIME(),NOW(),YEAR(),MONTH(),DATEOFMONTH() - 조건 함수:
IF(),CASE(),WHEN(),COALESCE() - 수학 함수:
ABS(),ROUND(),CELING(),FLOOR()
- 집계 함수:
- 조건 및 논리 연산자: 마찬가지로 논리연산자를 조건으로 사용해 데이터를 필터링할 수 있다.
- 비교 연산자: 등호, 부등호
- 논리 연산자:
AND,OR,NOT IN: 값이 주어진 목록 안에 있는지 확인BETWEEN: 값이 특정 범위 안에 있는지 확인LIKE: 문자열 패턴을 비교하여 일치하는 값이 있는지 확인
- 집합 연산자: 두 개 이상의 결과 집합을 결합하거나 비교하는데 사용한다.
UNION: 합집합(UNION ALL은 중복을 제거하지 않음)INTERSECT: 교집합EXCEPT또는MINUS: 차집합(A-B)
SQL 꿀팁
- SQL 코드는 대소문자 구분을 하지 않지만, 용도에 따라 구분하는 것이 권장된다.
- 문장의 끝은 마침표. SQL 코드의 끝은 세미콜론!
- 따옴표의 용도는 고유값
- 주석 처리는 이렇게
-- SELECT * FROM table; 한 줄 주석은 이렇게!
/*
여러 줄 주석은 이렇게!
SELECT * FROM table
WHERE memid >= 10;
*/- 키워드 순서
SELECT ~~~
FROM ~~~
INNER JOIN ~~ ON ~.~ = ~.~
WEHRE ~~~
GROUP BY ~~~
HAVING ~~~
ORDER BY ~~~
LIMIT ~ OFFSET ~ 키워드 정리
- DBMS: Database Management System. 데이터를 관리하고 저장하기 위한 소프트웨어 시스템을 가리킨다.
- 관계형 데이터베이스 관리 시스템 (RDBMS): 가장 일반적으로 사용되는 DBMS로, 데이터 테이블 형식으로 저장하고 관리한다. SQL로 데이터를 확인하고 조작한다. 대표적으로 Oracle Database, MySQL, Microsoft SQL server, PostgreSQL, SQLite 등이 있다. 특히 SQLite는 파일 단위로 RDBMS를 관리할 수 있기 때문에 앱개발에서 선호된다고 한다.
- NoSQL: 관계혀 데이터베이스 시스템에 비해 제약조건이 완화되고 대규모로 저장하거나 처리할 수 있는 데이터베이스 유형. 스키마의 유연성이 높고 확장이 우수하며, 다양한 데이터 모델을 제공한다고 한다. MongoDB, Cassandra, Redis, Couchbase 등이 있다.
- 메모리 데이터베이스: 데이터를 메모리에 저장하고 처리하는 유형의 데이터베이스. 빠른 응답시간이 가장 큰 장점! 실시간 분석이나 캐싱에 사용된다고 한다. Neo4j, Amazon Neptue 등.
- 시계열 데이터베이스: 시간 순서로 데이터를 저장하고 처리하는 데이터베이스. IoT 센서 데이터, 로그 데이터 등의 시계열 데이터를 처리하는 데 사용한다. 시간 기반 쿼리와 집계를 지원하며, 대용량 데이터를 효율적으로 저장할 수 있다고 한다. InfluxDB, TimescaleDB 등.
- 데이터 모델링: RDBMS에서, 현실에 존재하는 데이터를 데이터 베이스 객체로 만드는 과정. 개념적 모델링, 논리적 모델링, 물리적 모델링으로 구성된다.
- SQL: Structured Query Language; 데이터베이스에서 데이터를 저장, 검색, 수정, 삭제하는 데 사용되는 표준화된 질의 언어. query라는 뜻에서 알 수 있듯이 데이터베이스에 정보를 요청하고 필요한 데이터를 가져오는 기능을 갖는다.
- 데이터 모델: 현실 세계를 추상화하여 데이터베이스를 설계하는 과정에서 사용되는 개념적인 틀, 청사진을 가리킴
- 추상화: 복잡한 현실 세계를 단순화하거나 일반화하여 특정 측면 혹은 특징에 집중하는 과정을 가리킴
- 복잡성 감소, 일반화, 핵심 강조(정보의 선택과 집중), 모델링 등을 위해 사용된다고 한다. 그중에서도 모델링은 복잡한 시스템이나 데이터를 간결하고 이해하기 쉬운 형태로 표현하는 데 사용된다.
- Entity(개체): 데이터 모델링에서 식별 가능한 개체로, 데이터베이스에 정보를 저장하고 관리하기 위한 구조를 정의할 때 필요하다. E-R diagram에서는 사각형으로 표현된다. 비즈니스 레벨에서는 도메인에서 중요한 개념이나 객체를 가리키고, RDBMS에서는 데이터 테이블의 이름으로 생각해 볼 수 있다.
- Attributes(속성): RDBMS에서 의미를 지니는 가장 작은 데이터 단위이다.(문법적인 의미를 지니는 최소단위인 형태소나, 생명활동의 기본 단위인 세포와 비슷하게 생각하면 편하다!) entity의 세부 정보를 가리키거나 relationship을 설명하는 데 사용되는 가장 작은 데이터 단위라고 한다.
- 고객이라는 entity에 들어갈 수 있는 속성은? 이름, 주소, 전화번호, 이메일, 가입일자, 등급 등!
- Relationship: 개체 간 관계(상호작용)를 나타냄. E-R diagram에서는 마름모로 표현된다.
- one-to-one: 일대일 관계. 예) 사용자 테이블과 프로필 테이블이 있을 때 사용자는 하나의 프로필만 가지며, 각 프로필은 특정 사용자에게만 연결되는 경우.
- one-to-many: 일대다 관계. 예) 저자 한 명이 여러 개의 책을 씀 - 저자 테이블과 책 테이블이 있을 때 각 저자별로 여러 개의 책이 연결되지만 책은 저자 한 명에게만 속하는 경우.
- many-to-many: 다대다관계. 예) 장르와 책의 관계 - 책 테이블과 장르 테이블이 있을 때 각 책은 여러 개의 장르가 연결되고 각 장르에는 여러 책이 연결되는 경우.
- Relation: 데이터 테이블을 가리키며 테이블 이름이나 구조를 설명하는 데 사용됨. relationship과 단어가 비슷하기 때문에 혼동하지 말 것!
- Data table structure

- 데이터 테이블은 우리가 익히 아는 것처럼 엑셀의 스프레드 시트처럼 생겼으며, 행과 열로 구성된다.
- 열의 경우 column, attributes, field로 불린다.
- 행은 row, record, isntance, tuple로 불린다.
- entity 내 속성의 개수는 degree이다. 예를 들어 어떤 테이블에 들어있는 속성이 3개라면, degree가 3이라고 표현한다.
- relation 내 튜플의 총개수는 cardinality라 부른다. python의 length와 비슷하다.
참고자료
'SQL' 카테고리의 다른 글
| [2강] 개발환경 세팅 및 Jupyter Notebook 기초 실습 (0) | 2024.03.13 |
|---|